Pharma Hell on Earth: The Odyssey of Surgisphere
How every observational study showing COVID vaccine efficacy now looks like a repeat of the Surgisphere fraud

I had to interrupt my previous plans for this weekend when something kicked off on twitter which has unravelled what could be the biggest Pharma scandal of all time.
And it was prompted by this question posted by the amusingly enigmatic Jurassic Carl:

Followed by a suitably captioned version of the famous Litovchenko painting of Charon carrying souls across the river Styx as encountered in Greek mythology such as in Homer’s Odyssey.

Of course most will know that Hades is the god of the underworld and not exactly a good guy to be revered. Which is why all these terms are lapped up by people who really want to bash you with their demonic symbolism. And it’s really not the sort of thing you want to see in medicine.
Which made OHDSI (Odyssey, get it?) so creepy when we saw all the names they had attached to its derivates some time back… “White Rabbit”, “Rabbit in a Hat” and HADES at the end of the whole pipeline. All very fluffy stuff really, if you’re into the Greek underworld stuff1.
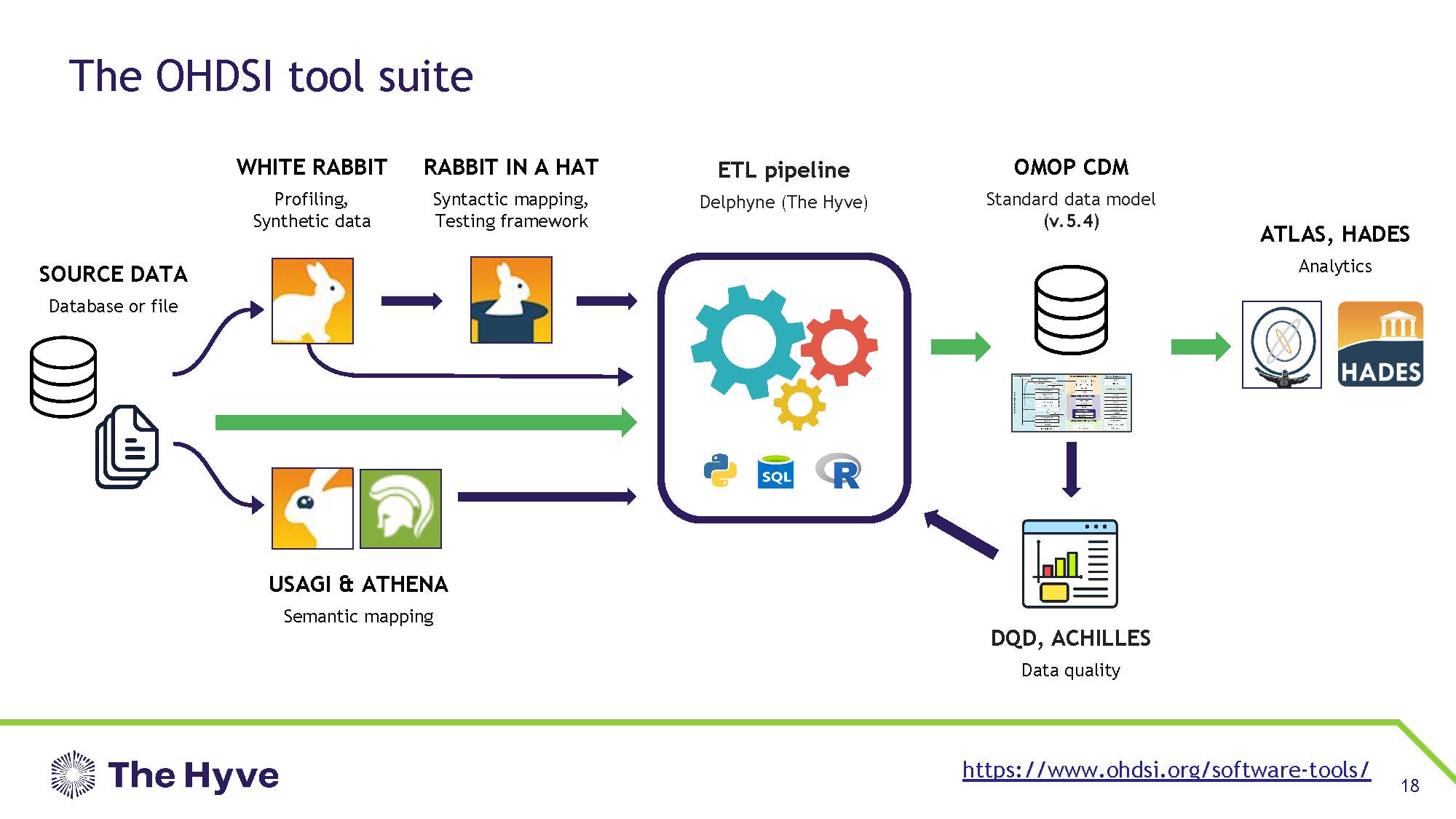
What the Hell is OHDSI?
I have to jump in early here to explain what OHDSI is so you will understand the rest of the story, which is a doozy. You see OHDSI is an organisation or a framework that is supposedly intended to curate health data from multiple institutions, so researchers can use that data for honest research.
In general, when you go to a hospital you carry with you a whole bunch of useful health data such as your age, ethnicity, drug history, medical history, family history, smoking etc etc. In theory we can use all that information from the billions of people entering hospital to see what drugs and risk factors might influence health outcomes.
Sounds good right? Unfortunately every hospital has its own database and they don’t usually talk to each other. So one way around this is to use common fields and languages (such as the OMOP model noted above) and try and get databases to talk to each other.
But in that process there needs to be ethical approval to skim your data, because you didn’t agree to it being shared with people that you don’t know, such as the Jeffrey Epstein affiliated group in the UK processing your personal data via China, right?
And getting ethical approval to skim health data in multiple countries at the same time is pretty much impossible, and was how we busted Surgisphere - currently the biggest medical fraud scandal in history.

And you don’t have to believe me about this idea that collating data from multiple systems in multiple countries is neigh on impossible - listen to the people trying to do it. According to Lora Frayling2 from the creepily named but NHS-based Simulacrum they fake it. In her words
“Data release processes can be inefficient, time-consuming and sometimes infeasible”

Note the partners for the HDI in the slide above - including NHS digital (linked to HDRUK, the data skimming organisation headed by Ben Goldacre) and the UKHSA.
When the going gets too tough, fake it till you make it with synthetic data.
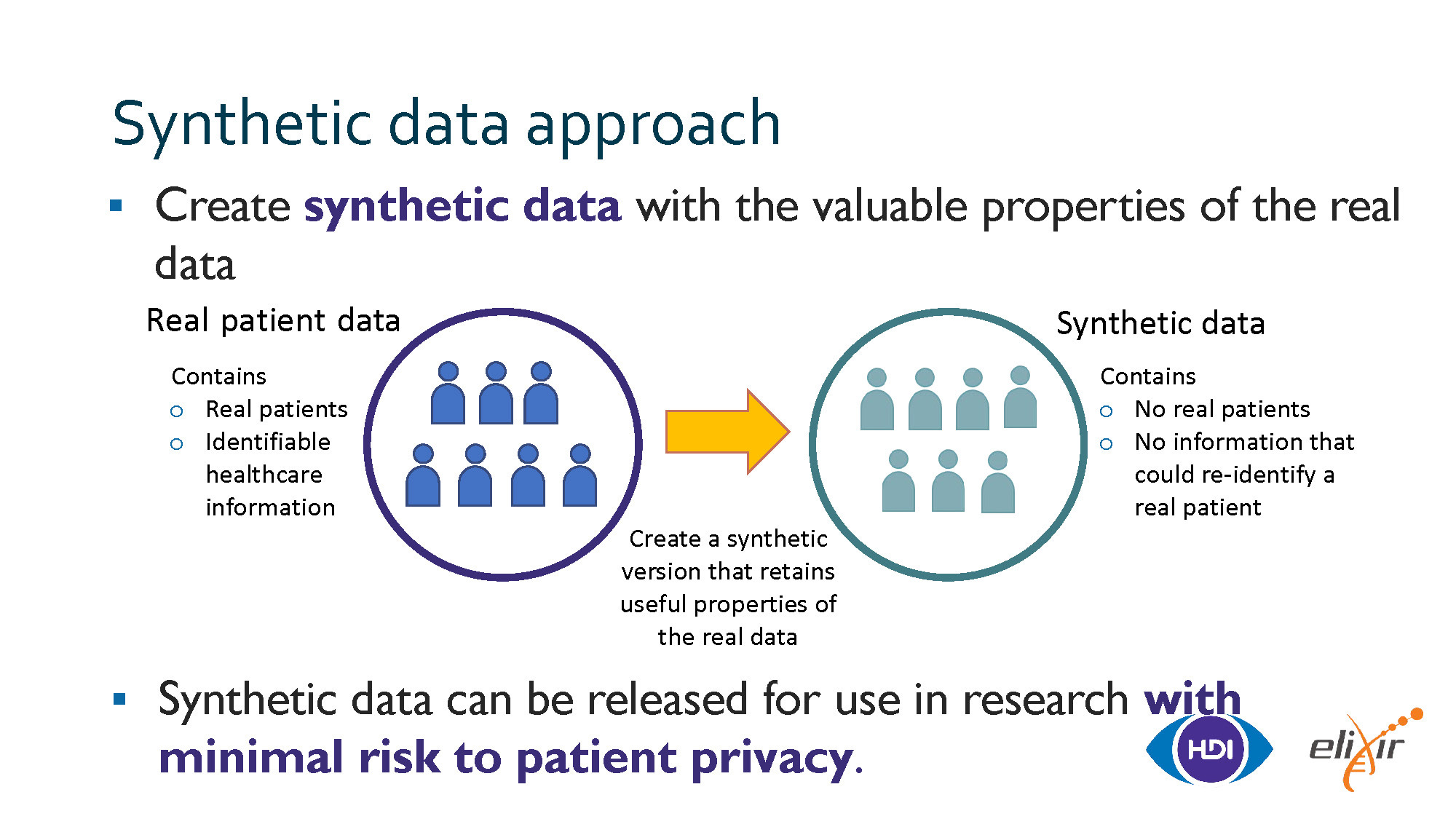
Yes, that’s right. The data isn’t real. Sure, real data might go into the system but what comes out after the “White Rabbit” and “Rabbit in a hat” has dealt with it is anybody’s guess.
And who is behind all this stuff?
Pharma of course. They don’t even hide it

If you want to join these people and their “data collaboration” you can - of course you have to jump through hoops to do it and be from an approved institute (where Pharma holds the purse strings and can keep an eye on what you’re doing).
Just join the journey (into the underworld, presumably)…

Whilst we’re here with the whole Greek stuff going on it’s worth noting that these guys chose the Caduceus as their symbol. If you don’t know your Caduceus from your Asclepius, you should read Clare Craig’s substack article3. Suffice to say - Caduceus = bad, Asclepius = good. Of course, Pharma tends to choose the caduceus as their logo.

Which I guess nicely ties into the whole “Hades” theme [eye roll]
")
So what has this got to do with Surgisphere? Pretty much everything really.
Surgisphere and the Big Data Con
Surgisphere was supposed to be one of the first incarnations of this idea that a huge data repository could be used to generate health data for research. It was on superficial inspection some sort of shell company and couldn’t possibly have handled the amount of data that they said they had access to, but the head of the company was a wide boy who went round the world telling people how cool this all was.
Pretty much everything about Surgisphere (registered as QuartzClinical) has been scrubbed from the internet but here is the Crunchbase archive of its employees.

They were supposed to be managing such a massive data repository (millions of patients, such that they found 98,000 hospitalised with COVID). All this supposedly managed by one doctor. Not happening, sorry.
Despite that, Sapan Desai was welcomed with a fanfare around the world including Brisbane in 2018 espousing how super this data repository was, earning Desai “The international grand prize in healthcare quality by the International Hospital Federation in 2015.”. Shame I missed the conference.

Despite the smiles he turned out to be a total fraud and have no idea how to verify the data set that he was handed on a plate (by someone, we still don’t know who). It was totally fabricated but he sold it to the world as real. And if we hadn’t made a fuss, he could have gotten away with it.
But he didn’t. For those who want to revisit the history Chris Martenson pretty much got the internet warriors together in one video that led to the demise and exposure of Desai. You might recognise some of the players (of course censored in the aftermath).
The bottom line from the Surgisphere fraud is this
The Surgisphere fraud was able to happen because:
(1) the authors claimed to use Electronic Health Record (EHR) data that could not be audited or verified and refused to release the data for public inspection.
(2) they used the backing of big institutions to support their authenticity, but those institutions were themselves conflicted by huge pharma payments.
It was a recipe for disaster and all that needed to happen for it to happen again was the same recipe.
And sure enough, we didn’t need to wait long. But before I go into that I just need to explain the Data Transparency Problem
The Data Transparency Problem
If you want to run a study, particularly to promote a drug (which by nature means that you are advertising a benefit), then you need to have data that is verifiable. Otherwise pharma can just make claims that their drugs work and can make a fortune on a fraud.
For a registered Randomised Controlled Trial (RCT) it is actually very difficult for Pharma to cheat. This is because the software used for the trial participants is locked and would need to be hacked. There are other ways to cheat of course, but it is not straightforward.
However, observational studies (where institutes look at the outcomes of interventions after the event rather than in a controlled trial) are very susceptible to data manipulation because you are now simply relying on the probity of the people collecting the data, there is no locked down software barrier to prevent them from either outright fraud or subconsciously manipulating the data to be favourable to a preconceived idea. A good example is the recent Scottish HPV vaccination study which was claimed to have shown an impact of the HPV vaccine but the authors skewed the data with older women in the unvaccinated arm, which is the main risk factor for developing cervical cancer.
To counter this problem the ICJME in 2016 asked for full data transparency

The proposal read as follows:
ICMJE proposes to require authors to share with others the deidentified individual-patient data (IPD) underlying the results presented in the article (including tables, figures, and appendices or supplementary material) no later than 6 months after publication.
A backlash ensued and within a year the proposal had been watered down to “authors must report a data sharing proposal and publish a data sharing statement”. Yawn.
What that meant was that the 2016 proposals were totally ignored and gave a blank cheque to pharma, because no studies would be mandated to release their data for public inspection as the 2016 proposal had requested.
The OpenSafely Hydroxychloroquine Scam
In a further twist of irony, the person who was the most vocal about making trial data open and transparent was Ben Goldacre. He was so forthright on this he sold books on it and did interviews even until 2016.

Yet something changed soon after this when he was appointed to head up HDRUK with the Epstein-affiliated Nicole Junkermann on the board and was given a prominent position at Oxford university (academic home of the UK vaccine industry).

HDRUK was an institute convened by the UK health minister (Matt Hancock) and the NHS in order to collate the health data of UK NHS patients (without their explicit consent) for research purposes. It was linked to a repository overseen by Ben Goldacre called OpenSafely run out of Oxford which was supposed to be used by researchers for the same purpose of giving them access to patient level data.

You may notice that the partners are interesting - Nuffield/Oxford is the home of the Astrazeneca vaccine and TPP is a Chinese company running the software your GP types into. EMIS is another health records company.
So Opensafely can take your health data and do what it wants with it, including having it processed in China.
The first thing that OpenSafely did was publish a paper during COVID that, like the Surgisphere paper did, tried to show that hydroxychloroquine was not effective for COVID. Except it conveniently left out the fact that the population it studied had less than half the mortality of the rest of the UK for COVID during this time, at 0.2%.

In that paper was a massive list of conflicts of interest but the worst irony was the Data Sharing Statement, for which 4 years earlier Goldacre was the most vocal proponent of full data transparency. But, no, you can’t see this data. Just trust us that hydroxychloroquine doesn’t work (when it clearly did with such a low fatality rate).

As far as the parallels to the Surgisphere paper go (it was successful at stopping all trials conducted around the world for hydroxychloroquine in COVID) this paper of Goldacre’s, which fulfilled the criteria necessary to create a fraudulent paper listed above, helped stop any chance of hydroxychloroquine research being resurrected.
But there was one other paper that was even worse. That was the Lane paper, by first author Jennifer Lane - an otherwise unheard of orthopaedic registrar.

Published in the same journal (Lancet Rheumatology) as the Goldacre OPENsafely paper and making an impossible claim:
The impossible claim was that they (meaning Jennifer Lane as the first author, without any formal grounding in research) found a cohort of nearly a million hydroxychloroquine users from 14 databases in the world of whom one third (over 300,000 people) were also taking azithromycin.
The result of the study was that hydroxychloroquine and azithromycin increased your risk of death.

The problem was, that the combination of hydroxychloroquine and azithromycin is not used as a treatment for rheumatoid arthritis or any condition. The whole paper had no basis on which to find such a cohort of 300,000 people - international databases or not.
And no, you can’t see the data. And guess who provided it? OHDSI did. It’s in their data non-sharing statement (which sounds like they are sharing data but they aren’t because the patient-level data is blocked).

In fact this study was so impossible, outside of the 300,000 combined drug users, that it came with a 136 page appendix. Appendices of this length are in practice only ever seen in pharma studies, they would never be generated by a lone researcher working even as part of a clinical group. In this case the group co-authors are mostly related to the OHDSI group with big players such as Patrick Ryan curating the data for Jennifer Lane and with a lot of influence from IQVIA, the largest medical data curator in the world and data handler for a number of vaccine studies. The conflicts and acknowledgements read like a who’s-who for the Pharma industry and the first author probably had no idea what she was being fronted for. The paper has “pharma written and pharma curated” all over it.
So just to summarise what the existence of these Surgisphere-like papers means
Curated data sets are created by entities linked to pharma corporations taking in genuine health data (without express consent)
New data is synthesised by OHDSI or Opensafely (both using the same models) based on existing input data, but with the ability to manipulate as required
The data sets are NEVER released for public inspection (data sharing)
Papers are published by major institutes which are usually funded by pharma interests and appear to be genuine
For those who prefer this pictorially…

And for whatever reason the three groups that were determined to show you that hydroxychloroquine didn’t work (when we know that it did) were:
Surgisphere (proven fake),
OPENsafely (data withheld) and
OHDSI-IQVIA (data withheld).
All those organisations had these two things in common:
(1) the authors claimed to use Electronic Health Record (EHR) data that could not be audited or verified and refused to release the data for public inspection.
(2) they used the backing of big institutions to support their authenticity, but those institutions were themselves conflicted by huge pharma payments.
The Grand Finale - Penn and Everything
The realisation of the above was brought to the fore by this paper released recently, which ostensibly claims that the COVID mRNA (specifically Pfizer) vaccine prevented “long COVID” in kids by 95%. Here’s the headline

If you have been following along you should realise that the “Real-world effectiveness” label is a cliché from OHDSI-type publications.

Note that this is the same Patrick Ryan as featured in the Jennifer Lane paper earlier, and works for Janssen (which is Johnson & Johnson, one of the biggest pharma corporations in the world).
So, is this paper from University of Pennsylvania another OHDSI curated data set?
It sure is.
And apart from claiming that the COVID vaccines prevented “long COVID” using data that we are not allowed to see4….

the study itself claimed that the reason that “long COVID” was prevented by the COVID vaccines is that the COVID vaccines had a 96% efficacy at preventing infection. Here’s their data.

There is of course no possibility that this is real.
Even similarly “stacked” data from the CDC couldn’t get above 50% by fixing the data and most notably the whole “COVID vaccines prevent infection” dogma was destroyed when the CDC released the Massachusetts study which proved that the vaccines did not prevent infection.

Most people will remember that the narrative at that time shifted away from “prevents infection” to “prevents death”, partly as a result of the Massachusetts study which showed that there was no reduction in infection rate in the vaccinated during the “Delta” outbreak.

It seems that OHDSI didn’t get the memo though because their data was published in 2024 and claimed a 96% effectiveness against preventing infection, which had never been achieved anywhere.
So it was not possible.
It would mean that for every vaccinated person that you know that got COVID, there would be 24 vaccinated people that you knew that never got COVID.
Nobody knows a group of people like that - the claim is provably fake.
But it tells us one really really important thing.
You see there is a famous principle in law (e.g. US v Throckmorton) known as “Fraud vitiates everything”. It means that if someone lies about something, or uses false information that they pass off as real, then the presumption falls that any information derived from that is also false (or fraudulent).
And this applies to ALL the observational studies used to tell you that the COVID vaccines prevented infection.
All of them.
That applies to the University of Pennsylvania Yong Chen study quoted above, all the way back to the first study pretending that COVID vaccines prevented infection (92% quoted efficacy) by Dagan in Israel.

Bear in mind this study was thoroughly debunked by Prof Mark Reeder but shows the extent that invested interests will go to to create studies based on data that they claim is real but cannot be verified by anybody independently.
So, what did the UPenn researchers do when it was pointed out to them that their data was not verifiable, not credible, and because it was curated by Pharma via OHDSI almost certain to be Surgisphere-level junk?
They delete their accounts

Or, worse still, ignore and deflect. The worst example of this has to be handed to Jeffrey Morris, co-author on the Yong Chen “96% efficacy against infection” paper and co-author on multiple papers espousing the “real world effectiveness” of the COVID vaccines (all based on curated data which cannot be verified). His institute, University of Pennsylvania, is a well know Pharma money pit and hosts Drew Weissman the co-inventor of the very technology that was never tested but that you were forced to take to keep your job, even though it didn’t work. But I’m sure that’s just coincidence.
What isn’t coincidence is the use of the Alice in Wonderland analogy when your whole data set was subject to “White Rabbit Data Synthesis”

The response to which was damning from Grok, twitter’s AI - which explains the controversy and the derisory response
OHDSI and Data Synthesis: The post mentions "White Rabbit" and "Rabbit in a Hat," which are tools used in the OHDSI (Observational Health Data Sciences and Informatics) suite for data profiling and mapping. These tools are part of a framework designed to handle and analyze observational health data within the OMOP (Observational Medical Outcomes Partnership) Common Data Model. They help in understanding and transforming source data into a standardized format for analysis.
Controversy Over Data Privacy and Integrity: The user @Jikkyleaks expresses skepticism about the integrity of the data used in studies funded by pharmaceutical companies, suggesting that these data sets might be curated or manipulated. This skepticism is part of a broader discussion on data privacy and transparency in medical research, where access to raw data for independent verification is often limited.
Comparison with Medical Scandals: The post draws a parallel to historical medical data scandals, like the one involving Google DeepMind and NHS patient data, implying that similar issues could be present with the data sets used by OHDSI. This comparison highlights concerns about how health data is handled, shared, and potentially misused by third parties, echoing past incidents where patient data privacy was compromised.
Yet the twitter spat is irrelevant.
What this all means is that ALL the observational studies that were relied upon by public authorities to reinforce the false claim that the COVID vaccines prevented infection (and therefore the results of infection) must be considered fake unless their data is open to public scrutiny. Now that’s a problem, because all those studies were relied upon by every defendant in every vaccine mandate case in the courts, and every government dictat that mandated your vaccine for work relied on those very publications.
How do we find out whether these studies are fake?
It will require government or legal action, because they are all hidden behind the same data “non-sharing” agreements.
The worse offenders are those that have the two criteria listed above but I’ll repeat again here:
(1) the authors claimed to use Electronic Health Record (EHR) data that could not be audited or verified and refused to release the data for public inspection.
(2) they used the backing of big institutions to support their authenticity, but those institutions were themselves conflicted by huge pharma payments.
I’ll add a third
(3) the authors are affiliated directly or indirectly with OPENsafely, OHDSI or IQVIA and/or have never verified their data against real-life patients
These criteria encompass most if not all of the observational studies that were relied upon by the courts and the government to impose vaccine mandates on the population and to prop up the pharma corporations’ false claims.
Every paper that fulfils these criteria must be allowed to be independently verified and if they are found to be fraudulent there has to be criminal consequences.
If not, we will rapidly approach our descent into pharma hell.
I’m not going peacefully.
[Note: For those on twitter the conversation is running under the hashtags #OHDSI, #EMRgate, #OHDSIgate, #PennGate and probably a few others]
There are other articles such as this historical piece.
The data sharing statement shows something commonly referred to as gatekeeping. Independent researchers or those who are not affiliated with a university that is currently receiving pharma funding can be blocked from accessing the data in case they write a paper showing that the claims are false. In the case of OHDSI data the researcher would not be allowed to access individual patient data that could be cross-checked against a real person, so the whole data set could be fraudulent and there would be no way of checking. This data sharing statement is therefore not worth the electrons used to make it.
Whenever I develop a little egotism about my sophistication, I encounter someone like you. THANKS for this piece; I learned a lot. Re Goldacre: "There is nothing so strongly fortified that it cannot be taken with money" --Cicero
And "You see there is a famous principle in law (e.g. US v Throckmorton) known as “Fraud vitiates everything”. It means that if someone lies about something, or uses false information that they pass off as real, then the presumption falls that any information derived from that is also false (or fraudulent)."
Your message is one of hope: in a day when everything seems contaminated, there exist stalwart academics who insist on the truth.
I'm sorry if writing this piece caused you to miss mouse family Christmas, or shopping for the mouselets, but I for one very much enjoyed this piece, right up the end, which I didn't enjoy - at all.
I didn't know how the courts, occupational groups and human rights departments were still justifying the mandates, but I'm shocked by the suggestion that they are believing the 95% efficacy against infection shite. One always assumed studies reporting such findings were completely fake (eg excluding people less than 3 weeks after the vax and more than 6 weeks after the vax, compulsory repeated testing of the unvaxd, and questions about the 95% being absolute or relative), and one would imagine something very wrong with the selection of the data, but I didn't imagine the problem was utterly corrupt, fake data sets managed by the product owners. But why should anyone be surprised by this? Everything else is fake so why not the data.
My only dissatisfaction with the article is that I'm left very angry that the people responsible for prolonging the destruction of lives (the courts, the occupational groups, the human rights departments) are so fking hopeless or so fking corrupt that they'd use these fking bad studies to support their declarations, when the absolute failure of the efficacy against transmission was so fking clear from the very beginning of the rollouts (Singapore Airport data out in May 2021).